Popularity and Ranking in a Finite World
In the last post, I discussed the difference between a few set operations (union, disjoint union, and intersection) and how experiences with content online can fall into these broad classifications. Earlier, I wrote a post about how math models in general can be useful for informing feature development.
Now we'll turn to specifics around interfaces, and how limits can inform our choices and expectations.
Limits and Organization
A lot of programming effort goes into working efficiently (usually searching and sorting) in an environment with "big" data. "How big is big?" Well, big and getting bigger. The main concern is how algorithms can stay efficient when the data size trends towards infinity.
At an interface level, there are practical limits we hit much earlier. People only have so much time, per task, per day, and per life, so it makes sense that at an interface level, showing each member of a set (for instance, every search result or every email you ever received) is impractical. And even if our process for understanding information may not be only linear in a "left to right, line by line" sense, it is still a process that takes time. Whether we can "chunk" and "scan" information or not, we comprehend things through time. In other words, what we experience through an interface from a dimensional perspective (for example, words on a 2-D interface - "a page") does not strictly confine our eye movements and comprehension to a particular order, but our past visual experiences will inform some process that takes place through time. The organization of a page suggests how to navigate it in while traveling through time (at our normal time-traveling speed of 1 second per second).
The point is, even if our data and the corresponding content is not so "big" (in the sense of needing to care a lot about the efficiency of storage/processing of it), when it comes to interfaces, we're going to hit interaction limits before we hit storage or speed limits.
Concrete physical (and virtualized space) limits
So far, this is a little abstract, but here are some examples of these kinds of limits:
- Top of fold (as in a newspaper)
- Front page (as in a newspaper)
- First page of a pagination or endless scroll (as in a web search)
- Top result (as in a web search)
- The size of the screen
(Note that how we are influenced by these limits, and when/why we go beyond them is beyond the discussion here.)
So with these limits in mind, even without "big" data, it's not hard to have content that is big enough to run into interface restrictions. As a matter of personal opinion, this is a more interesting and common problem than hitting software and hardware limits. In other words, we could stand to spend as much time talking about how we decide what to do when content is too big to fit in a box, on a page without scrolling, or in the first page of search results as we do with data sizes trending toward infinity.
To bring "big enough" data into an interface, we need to limit the content we present. Before we get into choices about what we might use and why, let's consider our options.
How to make a set smaller
To make a set (A) into a smaller set (B), we need a function. The simplest two functions that behave this way need to send some elements to nothing and/or send some elements to the same place.
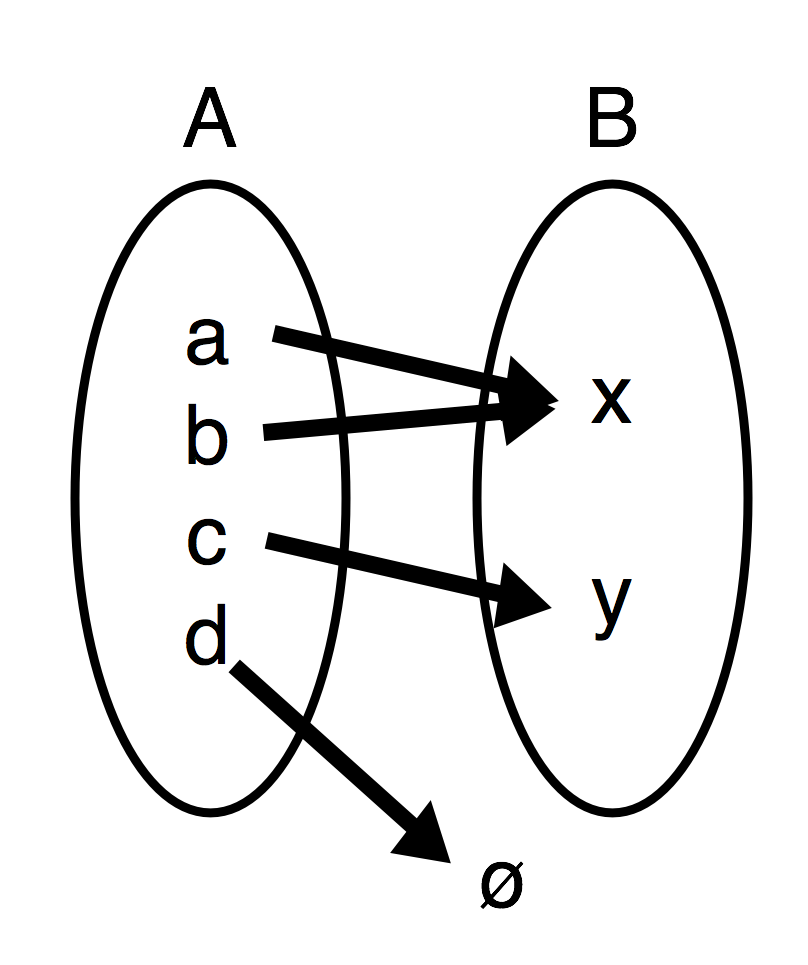
Note the arrow from d to null could have been eliminated, but is just there to specifically indicate how it might be treated by a total function that accepts it as input. A function that threw an error with d as input might be less desirable than one that leaves its output as an out of set value like null (ø) that could be removed from the results.
Now that we have a general idea of how we can make a set smaller, we can get to specifics of what functions we might use. First, we can have a filtering function that "kicks out" elements that don't adhere to some predicate, a "test" that can be true or false (a blog post that has "less than 2000 characters" or "created less than 24 hours ago" are both examples of predicates). Second, we could also use predicates like those make groups of posts that adhere to a condition. In this case, we would keep both groups, not filtering but rather partitioning them into 2 separate lists. An alternative view of this is that they haven't been physically "separated," but rather simply labeled, which means you have created a disjoint union out of them.
Sometimes that partitioning function can use more complex logic than a simple predicate, which enables several sets of objects to be separated/labeled in this way.
There are a few more particulars, such as the potential for considering every member of the partitioned subset to be equivalent, or at least representative of the subset, but the basic point is that to make a smaller set, you can either split into smaller sets (partition/group), or kick out some elements (filter).
(If you're interested in doing this in JavaScript, Ramda has some decent options: partition, groupBy, filter)
What to do with the smaller set
Anywho, now that we have a smaller set (or a few smaller sets) of content, we can put it into those limited spaces designed for limited time. But in all likelihood, it still doesn't all fit. Again, even without "big" data, our interface limits are more restrictive than the amount of content we're working with.
The solution to this is to sort the content in some way, and now we've come to a place where questions are hard to answer in the abstract, especially when we leave the land of numbers. It's easy to say "1 < 2" and "20 = 20."
But the following are a bit harder:
- How do we filter?
- How do we select just one top result?
- How do we group/label groups of content?
- How do we sort pieces of content (and groups)?
Predictive analytics (or reactive frustration after the fact) can give a certain type of answer to these questions: "Whatever gets the clicks and drives KPI's (revenue, signups, etc.) is good."
(By the way, there are more obvious signs that a company may be doing some awful things based on the effects of the product in "real life" or the working conditions of the place. Day to day, these are the algorithms that you might actually implement, rather than larger choices of what company or project to work with.)
Even if the answer to the above questions is, "we'll let the robots do it," then we're still left with questions of what kind of data, training, and models we give the robots (btw, I'm using "robots" as a cutesy term for AI/ML/Stats/etc.) to start with. Apocalypticly, they may act against us (perceptibly or not). Still very bad, they use bad (particularly old) data to lock us into a status quo to familiar and painful effect.
The failure to account for complexity while letting computers do this work (specifically of sorting, filtering, and grouping) has led to an interesting charge:
Machine learning is like money laundering for bias
— Pinboard (@Pinboard) June 19, 2016
Because a lot of these decisions (how exactly to sort/filter/group) are small and subtle, teams with a variety of perspectives, identities, and experiences can help uncover more ways that software can fail. Just to be clear though, even if it wasn't as lucrative to have diverse teams and leadership, it is part of how a just society should operate. I hate to even bring up the potential financial upside because as a goal, money has a certain way of becoming all consuming.
(The same goes for inclusive design by the way. Even if it is more costly/doesn't carry risk of violating regulations, making a good faith effort to support everyone is an issue of justice.)
"Objective" Sorts, Filters, and Grouping
With the exception of abstract numbers completely detached from anything in the material world, there are no "objective" methods to perform these tasks. Let's illustrate with an few examples:
You want to display projects on a crowdfunding site.
There are a million projects available for funding and you only have space to show ten to twenty on the home page. How do you decide which projects to never show (filter) vs. those to promote? On what criteria can you group them into subsections, and how do you order those subsections?
Phrased differently, the types of allowable projects come together as the union. When you separate them into categories, you form a disjoint union. If a potential funder supports or follows a project, then you've enabled an intersection between what they want and what the project offers (nudges/guesses to fund or follow, just as with video autoplay or search autocomplete do not indicate a similar operation).
And for the project creators, what do they find proximal? What 10 other projects should you see next to theirs? Is this an opportunity for intersection between multiple project makers? (Bring blog rolls back!)
Selecting projects at random isn't necessarily "objective" either. Maybe some projects are distressing or NSFW. But maybe that's also what makes them important, so if they are punished on the home page, maybe a theory of ranking fairly means highlighting them in a different way?
You want to show articles on a news site.
There are a million articles. What articles make it above the fold? How do you split the news into meaningful categories? What articles do you not allow, no matter how far down on the page? If you form a tiny category of two opposing sides of an issue, how dangerous or hollow does one have to be before it doesn't get its own "side" presented? (By the way, a sort (eg. of numbers) "...high, low, high, low..." is called a "fence").
If a position is represented disingenuously, should it be filtered? How much sycophancy/sequacity should be tolerated?
And again, what responsibility does content have to not be proximal to something dangerous? Even facts (details of self-harm/suicide) and method descriptions (including links with more detail) can carry risks with a wide circulation.
You want to add a news story to a social network feed.
It's a news feed that seems to tuck neatly beside your search feature. But because your model is a union/disjoint union free for all by default, the "opt-out" feature is built as a special case. You haven't yet built the special case to filter the news feed. Muted words aren't muted, and the site becomes worse. Take this reaction to this exact situation:
TW victim blaming
— Kelly Ellis (@justkelly_ok) January 18, 2019
It's really frustrating that @Twitter @TwitterSafety give users zero control what they see on their search tab (which was coopted for trends).
This awful and potentially extremely triggering headline has been on mine for more than 24 hours. pic.twitter.com/vU3eJwLXap
Similarly, for someone with epilepsy, a site with videos or gifs that autoplay would be more dangerous. I'd be happy to opt-in to that feature for myself if it meant someone else not having a seizure.
With an underlying model based on intersection, this feature, and these stories might not have even been there, as they wouldn't have been subscribed to.
The Interfaces of Tomorrow
Between Minority Report, Cowboy Bebop, Hackers, and so on, we have a pretty decent idea of what interfaces of the future should be like, at least if we want them to look cool. They seem to rely on two different schemes. The first is virtual/advanced materials. We're doing relatively well here with flat screens getting flatter and AR/VR advancements. We view this as a technical problem, which makes it interesting.
At the same time, we're forcing a lot of content into a union-based operation of feeds. How and why the feeds are bad is in the news pretty regularly, so I won't cover that here. We don't see this as a technical problem, partly because "tech" implies an unsustainable financial growth curve, so it gets pushed away as either "not really tech" or uninteresting.
But if we look back at what is possible in the interfaces themselves, they have deeply linked content (it can't even be confined to two dimensions or our traditional peripheral devices!) that is highly contextualized. These properties are antithetical to a "feed," and necessarily have a lot of forethought (or personalization) involved.
The future we could have here is somewhat informed by what we used to have. Custom pages, custom links (including "blog rolls") and custom designs. Homepages that provide some links to fun and informative content.
Of course none of these things are gone, just under-emphasized, but this can be just as bad. See Zeynep Tufekci's description of how this applies to censorship.

It's not just that the good has been buried by platforms. We also haven't recognized the potential in the cool UX of those futuristic interfaces (arguably the easier technical challenge, but still most definitely technical).
A feed is linear. A sprawling landscape of links is treelike. We're much better at laying out and traversing the first one. The latter, especially when defined arbitrarily, resembles an annoying "custom user forms" problem.
But trees are functors. We should be able to traverse them as easily as we do a list.
And think about how pretty everything could be. We've spent decades trying to put things into boxes on the web, and it's still hard. And are boxes all that nice to look at? If they are, why do we keep messing around with circles and hexagons and squircles?

The "prospect-refuge theory" (aka "savanna preference") suggests we like environments that represent opportunity and safety. This doesn't have to be overdone in a literal (and heavy-page) way, nor does it have to be as spartan as a nested directory.
All the pieces are there, but it's a future we'll need to chose.
Sort by Good, Filter out Bad, Group by Self-Identification
I'm not the one to make claims on what is "good and bad" in a holistic sense, but it seems like our drive to sort, filter, and group by what is profitable is increasingly showing itself to be a terrible idea. Or put another way:
"We're building a dystopia just to make people click on ads" - Zeynep Tufekci
"What is good?" and "what is bad?" are very old questions with many answers I don't know. But I'm pretty sure money has a bit of a shady past as compared with flourishing, generosity, justice, empathy, and kindness. Maybe we can sort and filter based on principles like that. In teams of technologists, we can have decent theories, but maybe we can ask sociologists and feminists when things get too technical.
As far as how to group people and content, maybe that's not for us to do? A sophisticated opt-in system could replace site tours of predetermined boxes we made. And again, we can ask sociologists, librarians, and queer studies scholars for help when things get too technical.
Given limited space full of relatively infinite content, "neutrality" is a broken model. We can sort and subgroup by what gets clicks. We can let our intuitions (and stale data) guide what should go to the top. We can rely on gameable metrics to determine it. We can make our only insistence be to promote conflict-driven media (sorting into fences) and raise the profile of weak and upsetting arguments. Lies are faster and cheaper to produce. An anti-sort (pulling random content) would ensure that they will be overrepresented.
Or we can have an editorial standard, promote opt-in as the default, intersectional model for interaction. We can remove comments sections and let video creators decide on the content that should be recommended around their videos, without being surrounded by hate and conflict-filled videos waiting to autoplay.
There is some hope in the intersectional model of intentional group and channel making with services like slack and other chat systems, and to some extent in the way a signed up person can choose their primary channels (subreddits) to follow in reddit. But for the mastodons, diasporas, and personal sites to flourish, twitter and facebook might have to decide to share.
If there's any hubris we show more than another when we make software, it's that by modeling a system, we somehow know how the system works. We might have a useful model, but all models are wrong.